国安部这份通报,真正重要的不是它说了什么,而是它没说什么
先说结论。
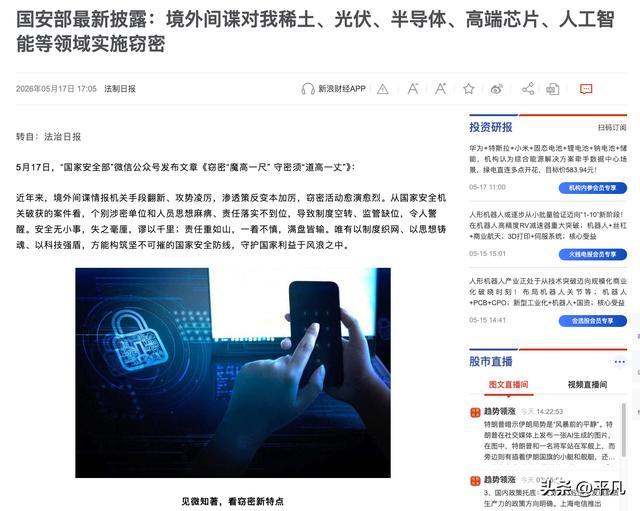
国安部5月17日这份通报,讲了境外窃密的新特点,也点名了稀土、光伏、半导体、高端芯片、人工智能等重点领域。这个判断当然重要。因为这些领域,正是今天大国竞争最硬的地方。
但我认为,真正值得警惕的,是它没有展开说的一件事。
2026年最有价值的技术窃取,可能不再是黑客入侵,不再是策反内鬼,也不再是拷贝U盘。
而是:向竞争对手的AI模型提问一百万次。
每一次看起来都像正常访问。每一次都可能是公开API调用。可这些问答积累起来,就可能变成训练另一个模型的数据。
这在技术上叫:模型蒸馏攻击。

攻击面,是怎么一步步变大的
信息安全里有个词,叫“攻击面”。
说白了,就是一个系统所有可能被人钻空子的入口。
过去几十年,攻击面一直在变大。
纸质文件时代,攻击面是物理空间。你想偷文件,得进办公室,得翻柜子,得接触档案。所以那时候的保密逻辑是:锁门、锁柜、专人保管。
个人电脑时代,攻击面变成了软盘、U盘、局域网。文件不用拿纸了,拷一下就走。所以保密逻辑变成:管设备、管接口、管内网。
互联网时代,攻击面变成了远程访问。钓鱼邮件、木马、远程控制、网站漏洞,都可以成为入口。所以保密逻辑变成:防火墙、杀毒软件、入侵检测。
现在进入第四代:云计算、AI、智能设备叠加在一起。
攻击面又变了。
很多入口看起来根本不像入口。
比如一个云盘链接。
比如一个错误的对象存储权限。
比如一个没有鉴权的Agent服务。
比如一个开放给用户调用的AI API。
这才是国安部通报里“网数智”条件下新型泄密风险最值得展开的地方。通报提到,少数单位和人员对智能设备数据采集、云端同步、权限调用等流程缺乏基本了解,存在“看不清、想不到、弄不懂”的问题。
这句话很重。
它说的不是某个人粗心,而是整个技术环境变了。
最危险的新入口:合法查询
传统窃密有一个特点:它通常要“越界”。
黑客要突破系统。内鬼要违反规定。间谍要伪装身份。至少从行为上看,边界很清楚。
但AI时代的新问题是:有些行为单次看,可能是合法访问。
例如,用户向一个大模型提问:
“请解释某种芯片设计思路。”
“请写一段高性能推理代码。”
“请把这个复杂问题拆成推理步骤。”
一次看不出问题。
一万次也可能只是重度用户。
但如果二十四万个问题围绕同一个能力区域反复追问,再把回答收集起来训练自己的模型,性质就变了。
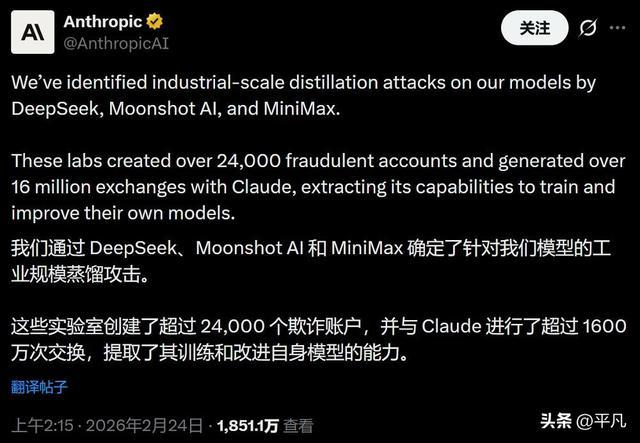
Anthropic在2026年披露过一起典型案例:它称三家中国AI公司通过约2.4万个欺诈账号,对Claude产生超过1600万次交互,用于提取模型能力。Anthropic把这种行为称为工业规模的蒸馏攻击,并表示它已经用分类器、行为指纹、跨账号协同检测等方式应对。
这里要注意一个事实边界:
“蒸馏”本身不是坏技术。
模型蒸馏本来就是AI行业常用方法。OpenAI自己也在API里提供过模型蒸馏能力,用大模型输出训练更小、更便宜的模型。
真正有争议的是:
未经授权,绕过限制,大规模提取别人的模型输出,再训练自己的模型。
这不是传统意义上的“偷文件”。
它更像是用公开窗口一点点搬走一个系统的能力。
为什么国安部点名这五个领域
通报里点名的几个方向很关键:稀土、光伏、半导体、高端芯片、人工智能。
它们不是随便列的。
这五个领域有一个共同点:都处在产业链的关键位置。
稀土是战略资源。央视此前披露,国内某稀土公司副总经理成某,将我国稀土收储品类、数量、价格等7项机密级国家秘密非法提供给境外,最终受到法律严惩。

注意,真正值钱的不只是“有多少矿”。
而是品类、数量、价格、储备节奏、供应预期。
这些信息如果被对手提前掌握,就可能影响谈判、定价、库存和产业链布局。
半导体和高端芯片则不同。
这里的窃密不一定只是为了复制中国技术,也可能是为了判断中国到底追到哪一步了。
你在哪个工艺节点卡住?
你哪类设备最缺?
你哪条路线最可能突破?
你哪些企业承担关键项目?
这些信息拼起来,就能反推出下一步该在哪里卡你。
人工智能更特殊。
因为AI的核心资产不只是论文、代码、参数和数据,还包括模型表现出来的能力。
一个模型会怎么推理,怎么写代码,怎么使用工具,怎么拒答,怎么绕开敏感问题,这些都能通过大量对话被观察。
也就是说,AI把“能力本身”变成了可以被查询、被记录、被模仿的对象。
这就是第四代攻击面。
文件里最严重的隐患,是“观念落后”
通报提到几类内部隐患:思想麻痹、观念落后、心存侥幸、卖密变节。
我认为最严重的是“观念落后”。
因为今天很多泄密,不是发生在“我知道这是机密但我故意卖掉”的场景里。
更常见的是:
我只是把工作笔记同步到个人云盘。
我只是把项目材料发给AI总结一下。
我只是把代码传到GitHub测试一下。
我只是把接口临时开到公网,方便同事调试。
我只是把链接设成“知道链接的人可访问”。
每一个“只是”,都可能是一个入口。
2025年,Cybernews曾报道腾讯云部分子域名存在严重配置错误,暴露了环境文件、硬编码凭证、内部源代码等内容,研究人员认为相关文件可能从至少4月起公开可访问,直到7月被发现。腾讯方面表示问题此前已被报告并修复。
这类事件最吓人的地方在于:它不一定需要高明黑客。
门可能本来就是开的。
只要有人扫到了,就能进去看。
真正有效的防护,不是喊口号
通报提出要以制度织网、以思想铸魂、以科技强盾。这个方向没问题。
但落到企业和科研机构,最关键的其实是四件事。
第一,重新盘点公开暴露面。
GitHub仓库、技术博客、论文补充材料、招聘JD、产品白皮书、会议PPT,这些东西单独看都不一定敏感,但组合起来可能很敏感。
第二,重新检查云权限。
所有云盘、对象存储、数据库、测试环境,都要确认到底是默认私有,还是默认公开。
很多事故不是被攻破,是权限模型没弄懂。
第三,重新定义AI使用边界。
什么材料可以发给外部AI?
什么代码不能贴进公开模型?
什么内部数据必须走私有化模型?
这些不能靠员工自觉,必须写成流程。
第四,把AI API访问控制纳入安全体系。
过去我们保护的是数据库。
现在还要保护模型能力。
谁能调用API?
每个账号能调用多少?
异常访问模式有没有报警?
大量相似问题是不是在抽取能力?
跨账号协同行为能不能识别?
这些都应该成为2026年的新安全标准。
最后说一句实话
国安部这份通报的价值,不只是提醒大家“境外窃密更猖獗了”。
它真正的价值,是把一个变化摆到了台面上:
泄密边界已经从文件、设备、网络,扩展到了云权限、智能设备、AI接口和模型能力。
过去,守密像守一间屋子。
后来,守密像守一张内网。
现在,守密像守一个不断对外响应的智能系统。
最麻烦的是,第四代攻击面里,很多入口都披着“正常使用”的外衣。
一次提问是使用。
一万次提问是重度使用。
一百万次结构化提问,可能就是能力抽取。
所以,AI时代的数据安全不能只盯着“有没有人偷文件”。
更要问一句:
有没有人在用合法访问,慢慢复制你的能力?
这才是新一轮技术竞争里,最容易被低估的风险。
永旺配资提示:文章来自网络,不代表本站观点。